
- Terraform module to deploy lambda that sends notifications about AWS CloudTrail events to Slack
- Configurations
- Rules
- Cloudwatch metrics
- About processing Cloudtrail events
- Slack App configuration:
- Terraform specs
This module allows you to get notifications about:
- actions performed by root account (According to AWS best practices, you should use root account as little as possible and use SSO or IAM users)
- API calls that failed due to lack of permissions to do so (could be an indication of compromise or misconfiguration of your services/applications)
- console logins without MFA (Always use MFA for you IAM users or SSO)
- track a list of events that you might consider sensitive. Think IAM changes, network changes, data storage (S3, DBs) access changes. Though we recommend keeping that to a minimum to avoid alert fatigue
- define sophisticated rules to track user-defined conditions that are not covered by default rules (see examples below)
- send notifications to different Slack channels based on event account id
This module also allows you to gain insights into how many access-denied events are occurring in your AWS Organization by pushing metrics to CloudWatch.
The module has three variants of notification delivery:
- Offers additional features, such as consolidating duplicate events into a single message thread. More features may be added in the future.
- The Slack app must have the
chat:writepermission. - Terraform configuration example
- Provides all the basic functionality of the module, but does not offer additional features and is not recommended by Slack.
- Terraform configuration example
- An optional feature that allows sending notifications to an AWS SNS topic. It can be used alongside either the Slack App or Slack Webhook.
All three variants of notification delivery support separating notifications into different Slack channels or SNS topics based on event account ID.
Rules are python strings that are evaluated in the runtime and should return the bool value, if rule returns True, then notification will be sent to Slack.
This module comes with a set of predefined rules (default rules) that users can take advantage of:
# Notify if someone logged in without MFA but skip notification for SSO logins
default_rules.append('event["eventName"] == "ConsoleLogin" '
'and event.get("additionalEventData.MFAUsed", "") != "Yes" '
'and "assumed-role/AWSReservedSSO" not in event.get("userIdentity.arn", "")')
# Notify if someone is trying to do something they not supposed to be doing but do not notify
# about not logged in actions since there are a lot of scans for open buckets that generate noise
default_rules.append('event.get("errorCode", "").endswith(("UnauthorizedOperation"))')
default_rules.append('event.get("errorCode", "").startswith(("AccessDenied"))'
'and (event.get("userIdentity.accountId", "") != "ANONYMOUS_PRINCIPAL")')
# Notify about all non-read actions done by root
default_rules.append('event.get("userIdentity.type", "") == "Root" '
'and not event["eventName"].startswith(("Get", "List", "Describe", "Head"))')
# Catch CloudTrail disable events
default_rules.append('event["eventSource"] == "cloudtrail.amazonaws.com" '
'and event["eventName"] == "StopLogging"')
default_rules.append('event["eventSource"] == "cloudtrail.amazonaws.com" '
'and event["eventName"] == "UpdateTrail"')
default_rules.append('event["eventSource"] == "cloudtrail.amazonaws.com" '
'and event["eventName"] == "DeleteTrail"')
# Catch cloudtrail to slack lambda changes
default_rules.append('event["eventSource"] == "lambda.amazonaws.com" '
'and "responseElements.functionName" in event '
f'and event["responseElements.functionName"] == "{function_name}" '
'and event["eventName"].startswith(("UpdateFunctionConfiguration"))')
default_rules.append('event["eventSource"] == "lambda.amazonaws.com" '
'and "responseElements.functionName" in event '
f'and event["responseElements.functionName"] == "{function_name}" '
'and event["eventName"].startswith(("UpdateFunctionCode"))')By default, every time Lambda receives an AccessDenied event, it pushes a TotalAccessDeniedEvents metric to CloudWatch. This metric is pushed for all access-denied events, including events ignored by rules. To separate ignored events from the total, the module also pushes a TotalIgnoredAccessDeniedEvents metric to CloudWatch. Both metrics are placed in the CloudTrailToSlack/AccessDeniedEvents namespace. This feature allows you to gain more insights into the number and dynamics of access-denied events in your AWS Organization.
This functionality can be disabled by setting push_access_denied_cloudwatch_metrics to false.
Rules must be provided as a list of strings, each separated by a comma or a custom separator. Each string is a Python expression that will be evaluated at runtime. By default, the module will send rule evaluation errors to Slack, but you can disable this by setting ‘rule_evaluation_errors_to_slack’ to ‘false’.
Example of user-defined rules:
locals = {
rules = [
# Catch CloudTrail disable events
"event['eventSource'] == 'cloudtrail.amazonaws.com' and event['eventName'] == 'StopLogging'"
"event['eventSource'] == 'cloudtrail.amazonaws.com' and event['eventName'] == 'UpdateTrail'"
"event['eventSource'] == 'cloudtrail.amazonaws.com' and event['eventName'] == 'DeleteTrail'"
]
rules = join(",", local.rules)
}This is much simpler than rules. You just need a list of eventNames that you want to track. They will be evaluated as follows:
f'"eventName" in event and event["eventName"] in {json.dumps(events_list)}'Terraform example:
local{
# EC2 Instance connect and EC2 events
ec2 = "SendSSHPublicKey"
# Config
config = "DeleteConfigRule,DeleteConfigurationRecorder,DeleteDeliveryChannel,DeleteEvaluationResults"
# All events
events_to_track = "${local.ec2},${local.config}"
}
events_to_track = local.events_to_trackBy default, the module expects rules to be separated by commas. However, if you have complex rules that contain commas, you can use a custom separator by providing the rules_separator variable. Here’s how:
locals {
cloudtrail_rules = [
...
]
custom_separator = "%"
}
module "cloudtrail_to_slack" {
...
rules = join(local.custom_separator, local.cloudtrail_rules)
rules_separator = local.custom_separator
}Note: We recommend addressing alerts rather than ignoring them. However, if it’s impossible to resolve an alert, you can suppress events by providing ignore rules.
Ignore rules have the same format as the rules, but they are evaluated before them. So, if an ignore rule returns True, then the event will be ignored and no further processing will be done.
locals {
ignore_rules = [
# Ignore events from the account "111111111".
"'userIdentity.accountId' in event and event['userIdentity.accountId'] == '11111111111'",
]
ignore_rules = join(",", local.ignore_rules)
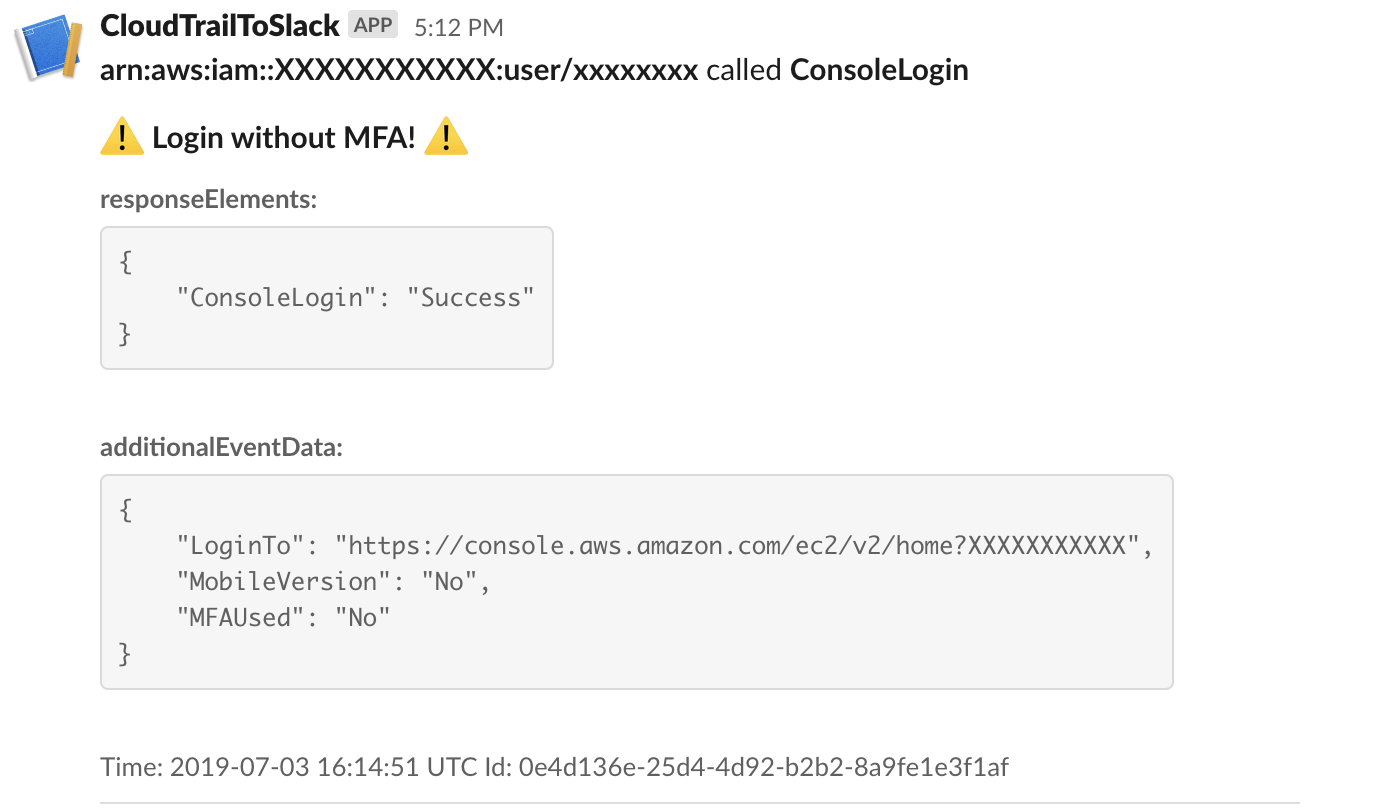
}CloudTrail event (see format here, or find more examples in src/tests/test_events.json) is flattened before processing and should be referenced as event variable
So, for instance, to access ARN from the event below, you should use the notation userIdentity.arn
{
"eventVersion": "1.05",
"userIdentity": {
"type": "IAMUser",
"principalId": "XXXXXXXXXXX",
"arn": "arn:aws:iam::XXXXXXXXXXX:user/xxxxxxxx",
"accountId": "XXXXXXXXXXX",
"userName": "xxxxxxxx"
},
"eventTime": "2019-07-03T16:14:51Z",
"eventSource": "signin.amazonaws.com",
"eventName": "ConsoleLogin",
"awsRegion": "us-east-1",
"sourceIPAddress": "83.41.208.104",
"userAgent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0",
"requestParameters": null,
"responseElements": {
"ConsoleLogin": "Success"
},
"additionalEventData": {
"LoginTo": "https://console.aws.amazon.com/ec2/v2/home?XXXXXXXXXXX",
"MobileVersion": "No",
"MFAUsed": "No"
},
"eventID": "0e4d136e-25d4-4d92-b2b2-8a9fe1e3f1af",
"eventType": "AwsConsoleSignIn",
"recipientAccountId": "XXXXXXXXXXX"
}- Go to https://api.slack.com/
- Click create an app
- Click From an app manifest
- Select workspace, click next
- Choose yaml for app manifest format
display_information:
name: CloudtrailToSlack
description: Notifications about Cloudtrail events to Slack.
background_color: "#3d3d0e"
features:
bot_user:
display_name: Cloudtrail to Slack
always_online: false
oauth_config:
scopes:
bot:
- chat:write
settings:
org_deploy_enabled: false
socket_mode_enabled: false
token_rotation_enabled: false
- Check permissions and click create
- Click install to workspace
- Copy Signing Secret # for slack_signing_secret module input
- Copy Bot User OAuth Token # for slack_bot_token module input
| Name | Version |
|---|---|
| terraform | >= 0.13.1 |
| aws | >= 4.8 |
| external | >= 1.0 |
| local | >= 1.0 |
| null | >= 2.0 |
| Name | Version |
|---|---|
| aws | 5.8.0 |
| Name | Source | Version |
|---|---|---|
| cloudtrail_to_slack_dynamodb_table | terraform-aws-modules/dynamodb-table/aws | 3.3.0 |
| lambda | terraform-aws-modules/lambda/aws | 4.18.0 |
| Name | Type |
|---|---|
| aws_lambda_permission.s3 | resource |
| aws_s3_bucket_notification.bucket_notification | resource |
| aws_sns_topic.events_to_sns | resource |
| aws_sns_topic_subscription.events_to_sns | resource |
| aws_caller_identity.current | data source |
| aws_iam_policy_document.s3 | data source |
| aws_kms_key.cloudtrail | data source |
| aws_partition.current | data source |
| aws_region.current | data source |
| aws_s3_bucket.cloudtrail | data source |
| Name | Description | Type | Default | Required |
|---|---|---|---|---|
| aws_sns_topic_subscriptions | Map of endpoints to protocols for SNS topic subscriptions. If not set, sns notifications will not be sent. | map(string) |
{} |
no |
| cloudtrail_logs_kms_key_id | Alias, key id or key arn of the KMS Key that used for CloudTrail events | string |
"" |
no |
| cloudtrail_logs_s3_bucket_name | Name of the CloudWatch log s3 bucket that contains CloudTrail events | string |
n/a | yes |
| configuration | Allows the configuration of the Slack webhook URL per account(s). This enables the separation of events from different accounts into different channels, which is useful in the context of an AWS organization. | list(object({ |
null |
no |
| dead_letter_target_arn | The ARN of an SNS topic or SQS queue to notify when an invocation fails. | string |
null |
no |
| default_slack_channel_id | The Slack channel ID to be used if the AWS account ID does not match any account ID in the configuration variable. | string |
null |
no |
| default_slack_hook_url | The Slack incoming webhook URL to be used if the AWS account ID does not match any account ID in the configuration variable. | string |
null |
no |
| default_sns_topic_arn | Default topic for all notifications. If not set, sns notifications will not be sent. | string |
null |
no |
| dynamodb_table_name | Name of the dynamodb table, it would not be created if slack_bot_token is not set. | string |
"fivexl-cloudtrail-to-slack-table" |
no |
| dynamodb_time_to_live | How long to keep cloudtrail events in dynamodb table, for collecting similar events in thread of one message | number |
900 |
no |
| events_to_track | Comma-separated list events to track and report | string |
"" |
no |
| function_name | Lambda function name | string |
"fivexl-cloudtrail-to-slack" |
no |
| ignore_rules | Comma-separated list of rules to ignore events if you need to suppress something. Will be applied before rules and default_rules | string |
"" |
no |
| lambda_build_in_docker | Whether to build dependencies in Docker | bool |
false |
no |
| lambda_logs_retention_in_days | Controls for how long to keep lambda logs. | number |
30 |
no |
| lambda_memory_size | Amount of memory in MB your Lambda Function can use at runtime. Valid value between 128 MB to 10,240 MB (10 GB), in 64 MB increments. | number |
256 |
no |
| lambda_recreate_missing_package | Description: Whether to recreate missing Lambda package if it is missing locally or not | bool |
true |
no |
| lambda_timeout_seconds | Controls lambda timeout setting. | number |
30 |
no |
| log_level | Log level for lambda function | string |
"INFO" |
no |
| push_access_denied_cloudwatch_metrics | If true, CloudWatch metrics will be pushed for all access denied events, including events ignored by rules. | bool |
true |
no |
| rule_evaluation_errors_to_slack | If rule evaluation error occurs, send notification to slack | bool |
true |
no |
| rules | Comma-separated list of rules to track events if just event name is not enough | string |
"" |
no |
| rules_separator | Custom rules separator. Can be used if there are commas in the rules | string |
"," |
no |
| s3_notification_filter_prefix | S3 notification filter prefix | string |
"AWSLogs/" |
no |
| s3_removed_object_notification | If object was removed from cloudtrail bucket, send notification to slack | bool |
true |
no |
| slack_app_configuration | Allows the configuration of the Slack app per account(s). This enables the separation of events from different accounts into different channels, which is useful in the context of an AWS organization. | list(object({ |
null |
no |
| slack_bot_token | The Slack bot token used for sending messages to Slack. | string |
null |
no |
| sns_configuration | Allows the configuration of the SNS topic per account(s). | list(object({ |
null |
no |
| tags | Tags to attach to resources | map(string) |
{} |
no |
| use_default_rules | Should default rules be used | bool |
true |
no |
| Name | Description |
|---|---|
| lambda_function_arn | The ARN of the Lambda Function |
Apache 2 Licensed. See LICENSE for full details.
https://github.com/fivexl/terraform-aws-cloudtrail-to-slack